In the field of artificial intelligence, Natural Language Processing (NLP) is widely recognized as the most significant tool for reading, deciphering, understanding, and understanding human languages. With NLP, machines can imitate human intelligence and abilities impressively, from text prediction to sentiment analysis to speech recognition.
Table of Contents
What is Natural Language Processing?

Language models play a crucial role in the development of NLP applications. It is nevertheless time-consuming to build complex NLP language models from scratch. For this reason, AI and machine learning researchers and developers swear by pre-trained language models. Transfer learning is a technique used to train models that perform a task using a dataset trained on another dataset. A new dataset is then used to repurpose the model for performing different NLP functions.
Pre-trained models: why are they useful?

- Then, we can use that pretrained model to solve our own NLP problem instead of building a model from scratch.
- Pre-trained models are designed to solve specific problems and need some fine-tuning, so they save a lot of time and computational resources when compared to writing a new language model.
NLP language models are available in several pre-trained categories based on their function.
10 Best NLP Models To Watch Out
1. BERT (Bidirectional Encoder Representations from Transformers)
![]()
BERT is a technique developed by Google for pre-training NLP. For language understanding, it relies on a new neural network architecture called the Transformer. The technology was developed to address the problem of neural machine translation or sequence transduction. As a result, it is well suited to any task which transforms input sequences into output sequences, such as speech recognition, text-to-speech conversion, etc.
Initially, the transformer contains two mechanisms: an encoder that reads text input and a decoder that creates predictions. Through BERT, language models can be created. So far, only the encoder mechanism has been utilized.
11 NLP tasks can be efficiently performed using the BERT algorithm. A dataset of 800 million words from BookCorpus and 2,500 million words from Wikipedia was used for training. BERT’s efficiency is exemplified by Google Search, which is one of the best examples. BERT is used for text prediction in other Google applications, such as Google Docs and Gmail Smart Compose.
2. RoBERTa (Robustly Optimized BERT Pre-training Approach)

The RoBERTa method is an optimized way of pre-training a self-supervised natural language processing algorithm. By learning and predicting intentionally hidden sections of text, the system builds its language model on BERT’s language masking strategy.
In RoBERTa, the parameters are modified. For example, larger mini-batches are used when training, the next sentence is no longer a pre-training objective in BERT, etc. Pre-trained models such as RoBERTa excel at all tasks on the General Language Understanding Evaluation (GLUE) benchmark and are ideal for NLP training tasks such as identifying questions, analyzing dialogues, and categorizing documents.
3. OpenAI’s GPT-3
With GPT-3, you can perform translation, answering questions, creating poems, doing cloze tasks, as well as unscrambling words on-the-fly. As a result of its recent advancements, the GPT-3 is also used for generating codes and writing news articles.
Statistics between different words can be managed by GT-3. There are over 175 billion parameters in the model, which are learned from 45 TB of text. With this, it is one of the largest pre-trained natural language processing models available.
The benefit of GPT-3 is that downstream tasks can be dealt with without needing fine-tuning. The model can be reprogrammed using the ‘text in, text out’ API, which lets developers write instructions.
4. ALBERT
With pre-trained language models becoming larger, downstream tasks become more accurate. The increased model size, however, results in slower training times, as well as GPU/TPU memory limitations. Google has developed a lightweight version of BERT (Bidirectional Encoder Representations from Transformers) to address this issue. Two techniques were used to reduce its parameters:
- Parameterized Embeddings: Here, the hidden layers and the vocabulary embeddings are measured separately.
- Sharing parameters across layers: This prevents the number of parameters from increasing as the network grows.
By using these techniques, memory consumption is lowered and the training speed of the model is increased. This loss is a BERT limitation with respect to inter-sentence coherence due to ALBERT’s self-supervised loss for sentence order prediction.
5. XLNet
Language models that use denoising autoencoding, such as BERT, perform better than models that use autoregressive methods. It is this reason why there is XLNet, which uses auto-regressive pre-training. It allows students to learn bidirectional context and overcomes the limitations of BERT using auto-regressive pre-training. A number of tasks, including natural language inference, document ranking, sentiment analysis, questions answering, etc., have been known to outperform BERT with XLNet.

6. OpenAI’s GPT2
In addition to using supervised learning on task-specific datasets for tasks such as question answering, machine translation, reading comprehension, and summarization, other natural language processing tasks are also generally approached with supervised learning. In OpenAI’s GPT2, trained on a new dataset of millions of web pages called WebText, language models begin learning these tasks even without explicit supervision. A wide variety of tasks are handled by the model and it produces promising results on a wide variety of tasks.
7. StructBERT
Pre-trained language models, such as BERT (and its robustly optimized version RoBERTa), have been gaining a great deal of attention in natural language understanding (NLU), achieving unparalleled accuracy for a range of NLU tasks, such as natural language inference, sentiment classification, question answering and semantic textual similarity. By incorporating language structures into pre-training, StructBERT extends BERT to a new model based on Elman’s work on linearization exploration. With structural pre-training, the StructBERT system produces surprising results on the GLUE benchmark (outperforming all published models), the SQUAD v1.1 F1 score at 93.0, and the SNLI accuracy at 91.7. In addition to question answering, sentiment analysis, document summarization, StructBERT may also assist in a wide range of NLP tasks.
8. T5 (Text-to-Text Transfer Transformer)
![]()
It has emerged as a powerful technique in natural language processing (NLP) to train a model on a data-rich task first and then fine-tune it for downstream tasks. A diversity of approaches, methodologies, and practices have resulted from the effectiveness of transfer learning. In order to set a new standard for transfer learning in NLP, Google suggests a unified approach. Accordingly, they propose treating NLP problems as text-to-text problems. A framework like this allows different tasks – summarization, sentiment analysis, question answering, and machine translation – to use the same model, objective, training procedure, and decoding process. A model named Text-to-Text Transfer Transformer (T5) is trained using web scraped data to come up with state-of-the-art results over a number of NLP tasks.
9. ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
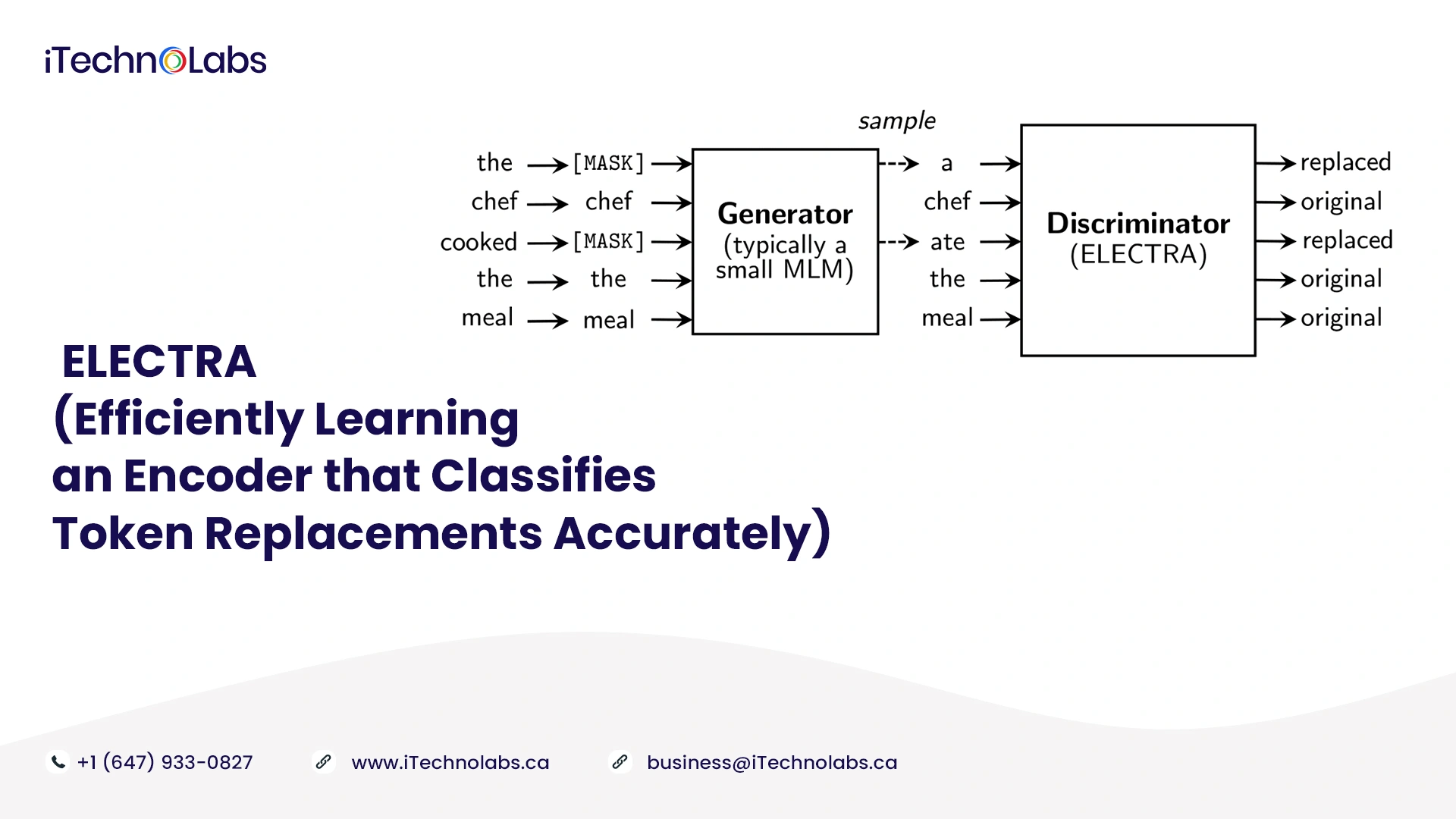
A masked language modeling (MLM) pre-training method uses Masking to replace some tokens in the input, then trains a model to recover the tokens’ original meaning. They tend to produce good results when applied to downstream NLP tasks, but they generally require a large amount of computing power. The experts propose an alternative called replaced token detection, which is more sample-efficient. Their approach replaces some tokens with plausible alternatives sourced from a small generator network instead of masking the input. Experts then train a discriminative model to identify whether each token in the corrupted input was replaced by a generator sample, instead of training a model that predicts the original identities of the corrupted tokens.
A masked-out subset of input tokens can be replaced with all input tokens in T5. The generator producing the replacement tokens is trained with maximum likelihood, making it not adversarial, despite the similarity to GAN. The ELECTRA is computationally efficient.
10. DeBERTa (Decoding-enhanced BERT with disentangled attention)
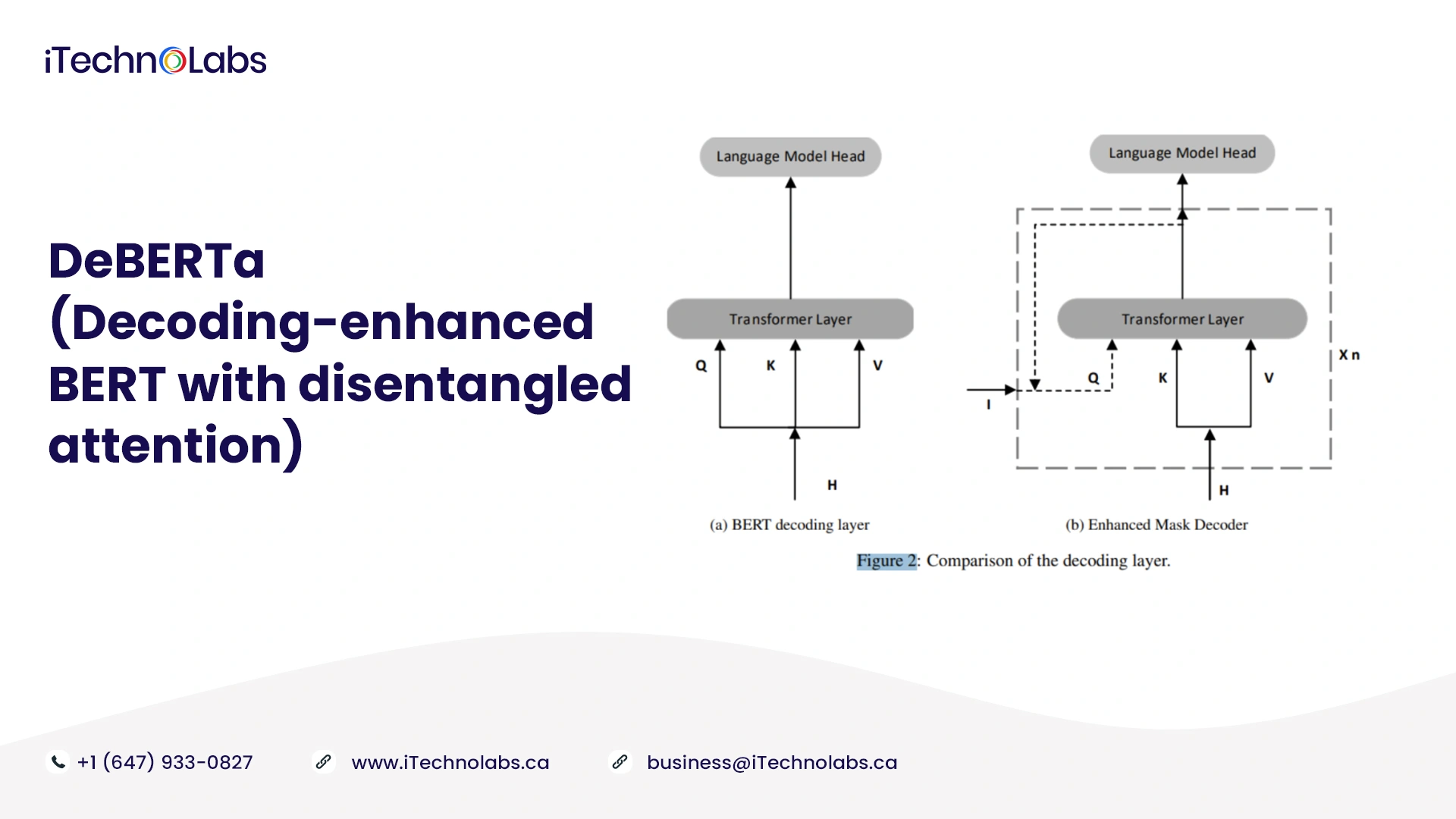
DeBERTa features two main improvements over BERT, namely an enhanced mask decoding system and disentangled attention. By encoding the content and relative position of a token/word, DeBERTa represents them as two vectors. While DeBERTa’s self-attention mechanism operates along content-to-content, content-to-position, and position-to-content lines, BERT’s self-attention consists only of the first two elements. In order to model relative positions within a sequence of tokens comprehensively, the authors propose that position-to-content self-attention is also required. Additionally, DeBERTa features an enhanced mask decoder, which gives the decoder both the absolute and relative position of the token/word. For the first time, a scaled-up variant of DeBERTa achieves better performance than humans on the SuperGLUE benchmark. As of the time of writing, Ensemble DeBERTA ranks first on SuperGLUE.
Are You Looking for an Artificial Intelligence Consulting Company?

It is quite clear that pre-trained nlp language models have many advantages. These models are a great resource for developers since they help them achieve precise output, save resources, and time on AI application development.
How do you choose the NLP language models that will be most effective for your AI project? This depends on several factors, including the scale of the project, the type of dataset, and the training methodologies used. Contact our AI experts if you would like to learn which NLP language model will help you achieve maximum accuracy and reduce your project’s time to market.
This can be accomplished by setting up a free consultation session with them, during which they can guide you with the right approach to developing your AI-based application.
FAQ’s for NLP Language Models
1. What is the language model in Natural Language Processing (NLP)?
The sole purpose of Natural Language Processing (NLP) is to render computers the ability to comprehend human language the way a human being does. To help achieve this purpose comes the language modelling in Natural Language Processing (NLP).
This is how the language models work –
- A language model in NLP analyse massive loads of text data
- Through the analysis, it determines the likeliness of a work occurring in a sentence
- With the help of such estimations, it constructs the rules of a language
- As more and more rules are constructed and more and more data is analysed, a language model enhances its linguistic knowledge
2. What are the various applications of pre-trained NLP models?
As the name suggests, pre-trained NLP models have been already trained to comprehend a human language and thereby perform tasks. Such models have been already fed with gigantic loads of text data in order to learn and understand a language.
You need not to train a language model from scratch when you can just implement a pre-trained language model for whatever purpose you want to use it for.
The diverse applications of pre-trained models for natural language processing (NLP) have been listed below. Take a glance –
- Name entity recognition
- Sentiment analysis
- Text summarisation
- Language translation
- Text generation
- Information retrieval, and much more
3. How do pre-trained NLP models work?
These models are trained on massive text datasets and use deep learning techniques like transformers to understand context, generate text, and perform tasks such as translation, summarization, and sentiment analysis.
4. Why are pre-trained NLP models important for AI development?
They reduce development time, improve accuracy, and allow developers to build advanced AI applications without needing extensive computational resources.
5. What are the benefits of using pre-trained NLP models?
Benefits include:
- Faster development
- High accuracy
- Reduced training costs
- Easy integration with applications
6. What tasks can NLP models perform?
NLP models can handle:
- Text generation
- Chatbots and virtual assistants
- Language translation
- Sentiment analysis
- Text summarization
7. Are pre-trained NLP models free to use?
Some models are open-source and free, while others require API access or subscription fees depending on the provider.
Tags: natural language models, nlp model, what are nlp models, nlp models, nlp models examples, pre trained ai models, what is nlp model, language models, natural language model, types of nlp models, best ai language model, nlp ai models, pretrained nlp models